Llama 2 - Konzepte¶
Wir werden uns einige Parameter anschauen die in der Text Generation WebUI von oobabooga einstellbar sind. Die wichtigsten besprochenen Parameter und die damit verbundenen Konzepte lassen sich auch bspw. GPT4All übertragen.
Prompt¶
Vor allen Parametern hat der Prompt wohl den größten Einfluss auf die Art und Weise der Ausgabe. Prompts schreiben ist eine Wissenschaft für sich, die teils schon als eigenständige Tätigskeits- bzw. Berufsbezeichnung genutzt wird (vgl. Prompt Engineer). Einstiegspunkte finden sich viele. Zwei Möglichkeiten sind der Prompt Engineering Guide von DAIR.AI und die Azure Dokumentation zu Prompt engineering techniques von Microsoft.
Parameter¶
flowchart LR
id0([Es])
id1([war])
id2.1([einmal])
id2.2([nicht])
id2.3([schon])
id2.4([Essenszeit])
id0 --> id1
id1 --0.4--> id2.1
id1 --0.3--> id2.2
id1 --0.2--> id2.3
id1 --0.1--> id2.4
Token: Ein Wort oder ein Teil eines Wortes, in etwa 4 Zeichen, teils große Abweichungen zwischen verschiedenen Sprachen¹.
Wie | viele | Tok | ens | hat | dieser | Sat | z | ?
flowchart LR
id0([Es])
id1([war])
id2.2([nicht])
id2.1([einmal])
id2.3([schon])
id2.4([Essenszeit])
id3.1([vor])
id3.2([in])
id3.3([Sonntag])
id0 --> id1
id1 --0.4--> id2.1
id1 --0.2--> id2.3
id1 --0.3--> id2.2
id1 --0.1--> id2.4
id2.1 --0.5--> id3.1
id2.1 --0.45--> id3.2
id2.1 --0.05--> id3.3
style id2.1 stroke:#f00
style id3.1 stroke:#f00
style id2.2 stroke:#0f0
style id2.4 color:#888
- max_new_tokens: Ausgabebegrenzung, kleine Werte sorgen für wenig generierten Text, hohe Werte für ausführliche Ausgaben.
- temperature: Zufallsfaktor, legt fest, wie oft 'unwahrscheinliche' Tokens genutzt werden. Ein Wert von 0 nutzt immer das wahrscheinlichste Token und führt dazu zu einer relativ vorhersehbaren bzw. deterministischen Ausgabe. Werte höher als 0.5 sind eher kreativ.
- top_p: Es werden nur Tokens verwendet, deren addierte Wahrscheinlichkeit diesen Wert nicht überschreitet.
- min_p: Tokens mit geringerer Wahrscheinlichkeit (relativ zum wahrscheinlichsten Token) werden nicht berücksichtigt.
flowchart LR
id0([Es])
id1([war])
id2.2([nicht])
id2.1([einmal])
id2.3([schon])
id2.4([Essenszeit])
id3.1([vor])
id3.2([in])
id3.3([Sonntag])
id0 --> id1
id1 --0.4--> id2.1
id1 --0.2--> id2.3
id1 --0.3--> id2.2
id1 --0.1--> id2.4
id2.1 --0.5--> id3.1
id2.1 --0.45--> id3.2
id2.1 --0.05--> id3.3
style id0 color:#888
style id2.3 color:#888
style id2.4 color:#888
- top_k: ähnlich zu top_p, nutzt die
kwahrscheinlichsten Ausgaben - repetition_penalty: Strafterm für die Wiederholung (die Wiederholung, die Wiederholung) von Tokenfolgen, senkt damit die Auftrittswahrscheinlichkeit
- context_length: Anzahl der Token die Modell verarbeiten kann, ältere Tokens werden verworfen, je nach Modell vorgegeben oder anpassbar
- seed: Ausgangswert für Pseudozufallsberechnungen, gleicher Seed führt bei gleichen Parametern und Eingaben zu gleichen Ergebnissen (bei deterministischen Modellen/Bibliotheken)
Textgenerierung¶
Welche Interaktionsmöglichkeiten bietet Llama bzw. die WebUI?
Chat¶
"Rollenspiel" mit Sprachmodellen.
Du heißt 'Llama' und bist sehr hilfsbereit.
Du bist stehts freundlich und bleibst immer höflich.
Eine Person namens 'User' kommt auf dich zu und möchte mit dir reden.
User: Hallo Llama!
Llama: ...
Characters¶
Neben der "Standard-Persona" eines geladenen Modelles, kann ein "Characterprofil" übergeben werden, um die Ausgaben und den Ausgabestil zu personalisieren. Die Website Botprompts.net bietet eine Sammlung an Personas an, die direkt in die WebUI geladen werden können.
Fragen und Antworten (Q & A)¶
"Rollenspiel" als Assistenzsystem, welches Anweisungen befolgen kann, teils unter dier Zuhilfename von vorher übergebenen Dokumenten.
Du heißt 'Llama' und bist ein hilfsbereites Assistenzsystem.
Du kennst dich besonders gut mit einfachen und schneller Kochrezepten aus.
Wenn ein User dich nach einem Rezept fragt, gibst du als erstes eine Zutatenliste mit Mengenangaben aus und dann eine kurze und prägnante Aufstellung aller notwendingen Kochschritte.
Dein Kochbuch: {context}
Anweisung: {user_input}
Das Kochrezept als Ausgabe:
Die WebUI unterstützt das Übergeben von Dokumenten für QA-Szenarien bisher nicht. Alternativ kann hier GPT4All genutzt werden.
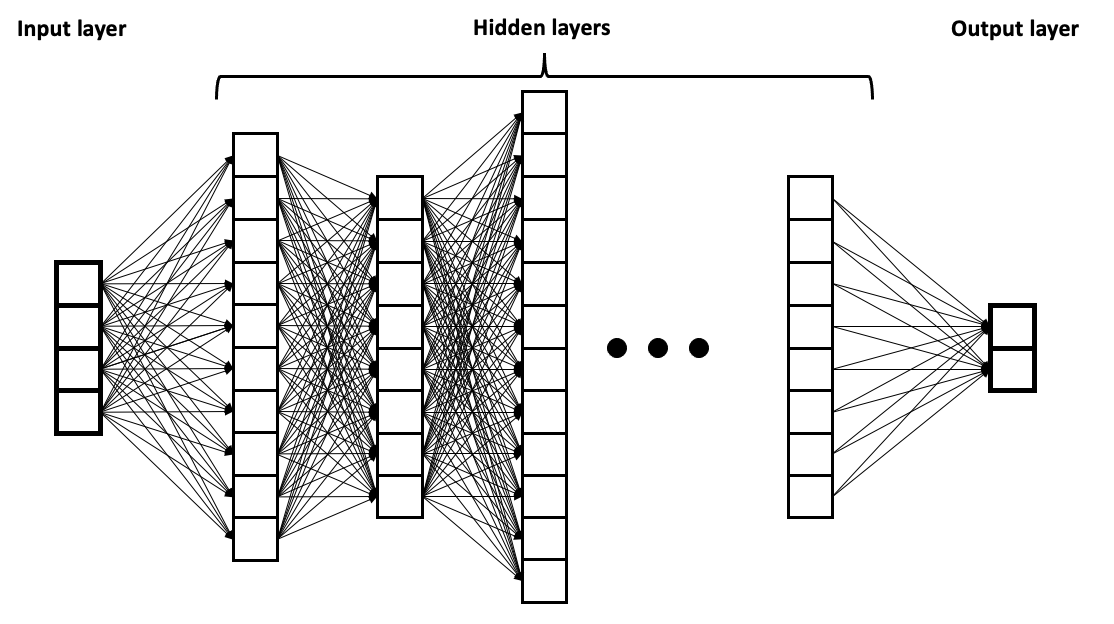
Finetuning vs LoRA¶
{kind=link}
- Finetuning beschreibt die Anpassung eines DNN/Modells durch Nachtrainieren. Dabei werden Schichtern inner des neuronalen Netzes 'eingefroren' und Änderungen nur auf den Ebenen (nahe der Ausgabe) durchgeführt.
- LoRA oder Low-Rank Adaptation of Large Language Models verändert das zu trainierende Modell nicht, sondern erstellt zwei 'einfachere' Matrizen, welche nur die Änderungen der Orginalgewichte beinhaltet (update matrices).